
مبانی مدلهای فضای برداری برای سئو
مدلهای فضای برداری میتوانند به یک تکنیک پرکاربرد برای
بهبود ارتباط و دقت نتایج جستوجو در بهینهسازی موتور جستوجو (SEO) تبدیل شوند.
در این مقاله، ما اصول اولیه
مدلهای فضای برداری و نحوه ارتباط آنها با سئو، از جمله تکنیکهای رایج و نقش زمینه و معناشناسی را بررسی میکنیم.
ما همچنین در مورد چگونگی مدیریت
مدلهای فضای برداری با مترادفها، تغییرات زبان و غلطهای املایی و همچنین توانایی آنها در بهینهسازی رتبهبندی تصاویر و سایر فایلهای چندرسانهای بحث میکنیم.
در نهایت، مدلهای فضای برداری را با تکنیکهای دیگر برای بهینهسازی نتایج جستوجو، مانند یادگیری ماشین و هوش مصنوعی مقایسه میکنیم با سایت لاینر همراه باشید.
چشم انداز جستوجو بهطور
مداوم در حال تغییر است و کاربران بهطور فزایندهای به موتورهای جستوجو برای یافتن اطلاعات، محصولات و
خدمات آنلاین متکی هستند.
در نتیجه، بهینهسازی موتورهای جستوجو (SEO)
به بخشی ضروری از بازاریابی دیجیتال تبدیل شده است؛ زیرا کسبوکارها و سازمانها در تلاش برای بهبود رتبه وبسایت و سایر
داراییهای دیجیتال خود در نتایج جستوجو هستند.
یکی از تکنیکهایی که بهتازگی بهطور فزایندهای در سئو محبوب شده است،
استفاده از مدلهای فضای برداری است.
در این مقاله، ما به اصول اولیه مدلهای فضای برداری و نحوه ارتباط آنها با سئو و همچنین بحث درمورد تکنیکها و ملاحظات مختلف در استفاده از آنها خواهیم پرداخت. همچنین مدلهای فضای برداری را با روشهای دیگر برای بهینهسازی نتایج جستوجو، مانند یادگیری ماشین و هوش مصنوعی مقایسه خواهیم کرد.

مدل فضای
برداری چیست و چه ارتباطی با سئو دارد؟
مدل فضای برداری یک نمایش ریاضی
از مجموعهای از اسناد یا موارد دیگر بهعنوان نقاط در
یک فضای چند بُعدی است. در زمینه بهینهسازی موتورهای جستوجو (سئو)، یک مدل فضای برداری میتواند برای نمایش مجموعهای از اسناد یا صفحات وب بر حسب کلماتی که
در آنها وجود دارد، با هر بُعد از فضا که بیانگر یک کلمه
متفاوت است استفاده شود.
سپس میتوان از فاصله بین دو نقطه در فضا برای اندازهگیری شباهت بین اسنادی که آنها نشان میدهند استفاده کرد.
یکی از کاربردهای رایج مدلهای فضای برداری در سئو، نمایش محتوای یک وبسایت
یا مجموعهای از صفحات وب بهمنظور شناسایی مهمترین یا مرتبطترین کلمات و عبارات برای یک موضوع خاص است.
این میتواند به موتورهای جستوجو کمک کند تا ارتباط یک صفحه وب را با یک جستوجوی خاص تعیین کنند و
وبسایت را بر اساس آن در نتایج جستوجو رتبهبندی کنند. برخی از الگوریتمهای معنایی اصلی مانند Sentence-BERT از مدلهای فضای برداری استفاده میکنند.
برای ایجاد یک مدل فضای برداری
برای مجموعهای از اسناد، اولین گام این است که کلمات
منحصربهفردی را که در اسناد ظاهر میشوند شناسایی کنید و برای
هر سند یک بردار ایجاد کنید که نشاندهنده فراوانی هر کلمه در آن سند باشد. سپس بردارهای حاصل را میتوان برای تعیین شباهت بین اسناد مقایسه
کرد.
بهعنوان مثال، مجموعهای از اسناد را در نظر بگیرید که همه مربوط به موضوع «سئو» هستند. مدل فضای برداری
برای این اسناد ممکن است شامل ابعادی برای کلماتی مانند «جستوجو»، «موتور»، «بهینهسازی» و «رتبهبندی» باشد. مقادیر این ابعاد برای یک سند
خاص نشاندهنده بسامد ظاهر شدن هر یک از این کلمات در
آن سند است.
یکی از راههای اندازهگیری شباهت بین دو سند در مدل فضای برداری،
محاسبه کسینوس زاویه بین بردارهای آنهاست. این کار با
گرفتن حاصل ضرب نقطهای بردارها و تقسیم آن بر حاصل ضرب قدر بردارها انجام میشود. مقدار به دست آمده از ۱- تا ۱ متغیر است که مقادیر نزدیک به ۱ نشاندهنده درجه تشابه بالاتر و مقادیر نزدیک به ۱- نشاندهنده درجه کمتری از شباهت است.
علاوهبر اندازهگیری شباهت بین اسناد، از مدلهای فضای برداری نیز میتوان برای شناسایی مهمترین کلمات یا عبارات برای یک موضوع خاص
استفاده کرد. این را میتوان با تجزیهوتحلیل بردارها برای مجموعهای از اسناد و شناسایی ابعادی که بالاترین
مقادیر را دارند انجام داد. این ابعاد احتمالاً با کلمات یا عباراتی مطابقت دارند
که بیشترین ارتباط را با موضوع دارند و میتوان از آنها برای بهینهسازی محتوای یک وبسایت یا صفحه وب برای
موتورهای جستوجو استفاده کرد.
بهطور کلی، مدلهای فضای برداری ابزار مفیدی برای بهینهسازی موتورهای جستوجو هستند؛ زیرا امکان نمایش و تحلیل
ریاضی محتوای یک وبسایت یا مجموعهای از صفحات وب را فراهم میکنند. با شناسایی مهمترین کلمات و عبارات برای یک موضوع خاص و بهینهسازی محتوای یک وبسایت بر این اساس، میتوان رتبه وبسایت را در نتایج جستوجو بهبود بخشید و شانس دیدهشدن آن را برای
مشتریان بالقوه افزایش داد.
چگونه
مدلهای فضای برداری به بهبود ارتباط و دقت نتایج جستوجو کمک میکنند؟
مدلهای فضای برداری (VSM) یک نمایش ریاضی از اسناد و کوئریهایی هستند که در سیستمهای بازیابی اطلاعات مانند موتورهای جستوجو استفاده میشوند.
آنها بر این ایده مبتنی هستند که کلمات و اسناد را میتوان بهعنوان بردار در یک فضای چند بعدی نشان داد، جایی که ابعاد با کلمات
موجود در واژگان اسناد مورد تجزیهوتحلیل مطابقت دارد.
با نمایش اسناد و کوئریها بهعنوان بردار، میتوان از عملیات ریاضی برای اندازهگیری شباهت بین آنها و رتبهبندی اسناد بر اساس ارتباط آنها با یک جستار معین
استفاده کرد.
یکی از راههای اصلی که VSMها به بهبود ارتباط و دقت نتایج جستوجو کمک
میکنند، در نظر گرفتن زمینهای است که کلمات در آن ظاهر میشوند. در موتورهای جستوجوی سنتی، یک کوئری معمولاً بر اساس وجود کلمات کلیدی منفرد با اسناد
مطابقت داده میشود، صرف نظر از نحوه استفاده آن کلمات کلیدی
در متن سند. این میتواند منجر به نتایج ضعیف شود؛ زیرا یک سند
ممکن است با یک کوئری مرتبط باشد، حتی اگر شامل همه کلمات کلیدی کوئری نباشد.
VSMها این موضوع را با در نظر گرفتن روابط بین کلمات در
یک سند، نه صرفاً حضور فردی آنها، برطرف میکنند. بهعنوان مثال، یک VSM ممکن است به کلماتی که اغلب در یک
سند ظاهر میشوند یا به کلماتی که در مجاورت یکدیگر ظاهر
میشوند وزن بیشتری اختصاص دهد. این به VSM اجازه میدهد تا معنی و زمینه سند را بهتر دریافت کند
و آن را با کوئریهای مربوطه مطابقت دهد.
روش دیگری که VSMها به بهبود نتایج جستوجو کمک میکنند، اجازه دادن به ترکیب
مترادفها و اصطلاحات مرتبط است. موتورهای جستوجوی سنتی اغلب برای تطبیق کوئریها با اسنادی که از کلمات متفاوتی برای بیان معنای مشابه استفاده میکنند، تلاش میکنند. بهعنوان مثال، یک درخواست جستوجو برای
«ماشین» ممکن است با سندی که از کلمه «خودرو» برای اشاره به همان مورد استفاده میکند مطابقت نداشته باشد.
VSMها میتوانند با نمایش مترادفها و اصطلاحات مرتبط بهعنوان بردارهایی که در فضای برداری
به یکدیگر نزدیک هستند، به این موضوع بپردازند. این به VSM
اجازه میدهد تا کوئریها را با اسنادی مطابقت دهد که از کلمات مختلف برای انتقال یک معنی استفاده میکنند و ارتباط و دقت نتایج جستوجو را بهبود میبخشد.
VSMها همچنین امکان ادغام بازخورد و ترجیحات کاربر را
در فرآیند جستوجو فراهم میکنند. در بسیاری از موتورهای جستوجو، کاربران میتوانند با کلیک روی اسناد خاص یا علامتگذاری آنها بهعنوان مفید یا غیر مفید، درباره ارتباط نتایج جستوجو بازخورد ارائه کنند. این
بازخورد میتواند برای تنظیم دقیق VSM، تنظیم وزن کلمات و اسناد مختلف برای مطابقت بهتر با ترجیحات
کاربر استفاده شود.
بهطور کلی، مدلهای فضای برداری ابزار قدرتمندی برای بهبود ارتباط و دقت نتایج جستوجو هستند. با در نظر گرفتن زمینهای که کلمات در آن ظاهر میشوند، امکان ادغام مترادفها و اصطلاحات مرتبط و ترکیب بازخورد کاربر، VSMها میتوانند کوئریها را با اسناد مرتبط با دقت بیشتری مطابقت دهند و در نتیجه تجربه جستوجوی بهتری را برای کاربران به ارمغان میآورند.

برخی از
تکنیکهای رایج مورد استفاده در مدلهای فضای برداری برای سئو چیست؟
مدلهای فضای برداری نوعی مدل ریاضی هستند که در بهینهسازی موتور جستوجو (SEO) برای تجزیهوتحلیل ارتباط یک وبسایت یا صفحه وب خاص با یک جستوجوی خاص استفاده میشوند.
این مدلها از بردارها یا نمایشهای عددی متن برای مقایسه شباهت بین اسناد مختلف و تعیین ارتباط آنها با یک عبارت جستوجوی معین استفاده میکنند.
چندین تکنیک متداول در مدلهای فضای برداری برای سئو استفاده میشود، از جمله فراوانی
اصطلاح-معکوس فراوانی متن (TF-IDF)، شباهت کسینوسی و نمایهسازی معنایی پنهان (LSI).
یکی از پرکاربردترین تکنیکها در مدلهای فضای برداری برای سئو، فراوانی اصطلاح-معکوس
فراوانی متن (TF-IDF) است. این تکنیک اهمیت یک کلمه یا
عبارت خاص را در یک سند با محاسبه فراوانی آن در آن سند و مقایسه آن با فراوانی
همان کلمه یا عبارت در اسناد دیگر در یک مجموعه مشخص میسنجد.
بهعنوان مثال، اگر یک کلمه
خاص اغلب در یک سند ظاهر میشود؛ اما به ندرت در اسناد دیگر دیده میشود،
اهمیت بیشتری برای آن در نظر گرفته میشود و در مدل فضای برداری
وزن بیشتری به آن داده میشود. این تکنیک برای شناسایی عبارات و
عبارات کلیدی مرتبط با یک عبارت جستوجوی خاص و رتبهبندی صفحات وب بر اساس ارتباط آنها با آن عبارات مفید
است.
یکی دیگر از تکنیکهای رایج مورد استفاده در مدلهای فضای برداری برای
سئو، تشابه کسینوسی است. این تکنیک شباهت بین دو سند را با محاسبه کسینوس زاویه بین
بردارهای آنها در فضای برداری
اندازهگیری میکند. تشابه کسینوسی بیشتر
نشان میدهد که اسناد شبیهتر هستند، در حالی که شباهت کسینوسی کمتر نشاندهنده شباهت کمتر اسناد است. این تکنیک برای شناسایی اسناد مشابه و گروهبندی آنها با هم مفید است که میتواند به بهبود دقت و ارتباط نتایج جستوجو کمک کند.
نمایهسازی معنایی پنهان (LSI) تکنیک دیگری است که در مدلهای فضای برداری برای سئو استفاده میشود. این تکنیک روابط بین
کلمات و عبارات درون یک سند را تجزیهوتحلیل میکند و الگوها یا مضامین پنهانی را که ممکن است
بلافاصله آشکار نشوند شناسایی میکند. بهعنوان مثال، کلمات
«سیب»، «میوه» و «آبمیوه» ممکن است همگی با مفهوم «آب سیب» مرتبط باشند، حتی اگر
عبارت «آب سیب» در سند وجود نداشته باشد. با شناسایی این الگوهای پنهان، LSI میتواند به بهبود دقت و ارتباط نتایج جستوجو با رتبهبندی صفحات وب بر اساس مضامین یا مفاهیمی که پوشش میدهند کمک کند.
سایر تکنیکهای رایج مورد استفاده در مدلهای فضای برداری برای
سئو شامل تجزیه ارزش منفرد (SVD) است که برای کاهش ابعاد بردار
سند و آسانتر کردن تجزیهوتحلیل آن و خوشهبندی که برای گروهبندی اسناد مشابه و بهبود دقت نتایج جستوجو
استفاده میشود.
علاوهبر این تکنیکها، مدلهای فضای برداری برای سئو نیز اغلب الگوریتمهای مختلف و تکنیکهای یادگیری ماشینی را برای بهبود بیشتر دقت
و ارتباط نتایج جستوجو در خود جای میدهند. بهعنوان مثال، الگوریتمهای پردازش زبان طبیعی (NLP) ممکن است برای تجزیهوتحلیل ساختار
و معنای متن مورد استفاده قرار گیرند، در حالی که الگوریتمهای یادگیری ماشینی مانند درختهای تصمیمگیری و شبکههای عصبی ممکن است برای تجزیهوتحلیل و طبقهبندی اسناد بر اساس محتوا و ارتباط آنها با یک کوئری جستوجو استفاده
شوند.
بهطور کلی، مدلهای فضای برداری ابزار مهمی در سئو هستند و راهی برای تجزیهوتحلیل ارتباط
صفحات وب با جستوجوهای خاص و بهبود دقت و
ارتباط نتایج جستوجو ارائه میدهند. مدلهای فضای برداری با استفاده از تکنیکهایی مانند TF-IDF، شباهت کسینوسی، LSI و همچنین الگوریتمهای مختلف و تکنیکهای یادگیری ماشینی، اطمینان میدهند که کاربران میتوانند مرتبطترین و مفیدترین اطلاعات را هنگام جستوجوی آنلاین بیابند.
چگونه
مدلهای فضای برداری، زمینه و معناشناسی کوئریهای جستوجو و اسناد را در نظر میگیرند؟
مدلهای فضای برداری نوعی مدل ریاضی هستند که در بازیابی اطلاعات و پردازش زبان
طبیعی برای نمایش اسناد متنی و جستوجوها بهعنوان بردارهای عددی در یک فضای چند بعدی استفاده میشوند.
این مدلها با استفاده از تکنیکهای متنوعی برای استخراج و رمزگذاری ویژگیها و روابط مهم بین کلمات و مفاهیم درون آنها، زمینه و معناشناسی کوئریهای جستوجو و اسناد را در نظر میگیرند.
یکی از راههایی که مدلهای فضای برداری، زمینه و معناشناسی را در
نظر میگیرند، از طریق استفاده از فراوانی اصطلاح-معکوس
فراوانی متن (TF-IDF) است.
این تکنیک بر اساس تعداد دفعات
ظاهر شدن آنها در سند یا کوئری در مقایسه با سایر اسناد
موجود در مجموعه، به عباراتی که اهمیت بیشتری دارند یا مربوط به یک سند یا کوئری
هستند، وزن بیشتری اختصاص میدهد.
بهعنوان مثال، اگر اصطلاح «سرطان» چندینبار در یک سند درمورد تحقیقات پزشکی ظاهر شود، وزن بیشتری نسبت به زمانی که فقط یک بار در سندی در مورد مُد آمده باشد به آن داده میشود. این به مدل کمک میکند تا زمینه و مفهوم سند یا کوئری را درک کند و نتایج مرتبط را بازیابی کند.
تکنیک دیگری که در مدلهای فضای برداری استفاده میشود، Stemming یا روش ساقهای است، که شامل سادهکردن کلمات به شکل ریشهای آنها
میشود، بهطوری که تغییرات یک کلمه بهعنوان یک واژه
در نظر گرفته میشود. برای مثال، «میوه»، «آبمیوه» و «میوهای»
همگی به شکل ریشه «میوه» منشعب میشوند. این به مدل کمک میکند تا معنای یک کوئری یا سند را درک کند و نتایج مرتبط را بازیابی کند؛ زیرا میبیند که این کلمات با یکدیگر مرتبط هستند و معنای مشترکی دارند.
مدلهای فضای برداری نیز اغلب از «کلمات توقف» استفاده میکنند که کلمات رایجی هستند که معمولاً در مرحله پردازش نادیده گرفته میشوند یا از متن حذف میشوند. این کلمات، مانند «یه»، «یک»، «ها»
و... به معنای زیادی در زمینه یا معنای متن کمک نمیکنند و اغلب میتوانند بدون تأثیر بر معنای کلی حذف شوند. با
حذف این کلمات، مدل میتواند روی اصطلاحات مهمتر تمرکز کند و معنای
متن را بهتر درک کند.
علاوهبر این، مدلهای فضای برداری ممکن است از مترادفها و اصطلاحات مرتبط برای
کمک به درک زمینه و معنای یک کوئری یا سند استفاده کنند. برای مثال، اگر کاربری
برای «ماشین» جستوجو کند، مدل ممکن است عبارات مرتبطی مانند «خودرو» یا «وسیله
نقلیه» را نیز برای بازیابی نتایج مرتبط در نظر بگیرد. این به مدل کمک میکند تا معنی و مفهوم گستردهتر کوئری را درک کند، نه
اینکه صرفاً روی اصطلاح خاص «خودرو» تمرکز کند.
در نهایت، مدلهای فضای برداری ممکن است از تکنیکهایی مانند نمایهسازی معنایی پنهان (LSI) و تخصیص دیریکله پنهان (LDA) برای استخراج و کدگذاری روابط پنهان بین کلمات و مفاهیم در متن
استفاده کنند. بهعنوان مثال، LSI از تجزیه
ارزش منفرد برای شناسایی الگوها و روابط درون متن استفاده میکند و آنها را در فضایی با ابعاد پایین نشان میدهد، در حالی که LDA از مدلهای احتمالی برای شناسایی موضوعات پنهان در متن استفاده میکند و آنها را بهعنوان مجموعهای از اصطلاحات وزنی نشان میدهد. این تکنیکها به مدل کمک میکنند تا معنا و زمینه متن را درک کند، نه
فقط تک تک کلمات.
بهطور کلی، مدلهای فضای برداری، زمینه و معنای کوئریهای جستوجو و اسناد را
از طریق تکنیکهای مختلفی از جمله وزندهی، ریشهیابی، کلمات توقف، مترادفها و تحلیل معنایی پنهان در نظر میگیرند. با در نظر گرفتن این
عوامل، مدل قادر است معنا و زمینه متن را با دقت بیشتری درک و نمایش دهد و منجر به
نتایج جستوجوی مرتبطتر و دقیقتر شود.
مدلهای فضای
برداری چگونه مترادفها و تغییرات زبان را در کوئریهای جستوجو و اسناد را مدیریت
میکنند؟
مدلهای فضای برداری، نمایشی ریاضی از کلمات یا عبارات در یک زبان معین هستند. این
مدلها برای تجزیهوتحلیل و درک روابط بین کلمات و
عبارات به منظور بهبود نتایج موتورهای جستوجو و بازیابی
اسناد استفاده میشوند.
یکی از راههای کلیدی که در آن مدلهای فضای برداری، مترادفها و تغییرات زبان را مدیریت میکنند، استفاده از بردارهای کلمه است.
بردارهای کلمه، نمایشهای ریاضی کلمات یا عباراتی هستند که بر
اساس زمینهای که در آن استفاده میشوند، هستند. این بردارها با تجزیهوتحلیل مقادیر زیادی از دادههای متنی و تعیین روابط بین کلمات یا عبارات ایجاد میشوند. بهعنوان مثال، اگر دو کلمه یا عبارت اغلب با هم استفاده میشوند، احتمالاً بردارهای کلمه مشابهی خواهند داشت.
یکی از راههای اصلی که در آن مدلهای فضای برداری، مترادفها و تغییرات زبان را مدیریت میکنند، استفاده از جاسازی
کلمات است. «جاسازی کلمات» نوعی بردار کلمه است که معنای یک کلمه یا عبارت را در یک
فضای برداری پیوسته نشان میدهد. این به مدل اجازه میدهد تا روابط بین کلمات یا عبارات مختلف را درک کند و مترادفها یا تغییرات زبان را شناسایی کند.
برای مثال، اگر یک عبارت جستوجو
حاوی کلمه «دویدن» باشد، مدل ممکن است از جاسازی کلمه استفاده کند تا بفهمد که این
کلمه با کلمات دیگری مانند «پریدن»، «راهرفتن سریع» و... مرتبط است. این به مدل
اجازه میدهد تا نتایج مرتبطتری را برای کوئری جستوجو کند، حتی اگر کوئری حاوی کلمات یا عبارات دقیق
استفاده شده در اسناد نباشد.
علاوهبر جاسازی کلمات، مدلهای فضای برداری نیز از تکنیکهایی مانند فراوانی
اصطلاح-معکوس فراوانی متن (TF-IDF) برای مدیریت مترادفها و تغییرات در زبان استفاده میکنند. TF-IDF اندازهگیری اهمیت یک کلمه یا عبارت در یک سند یا
مجموعهای از اسناد است. کلمات یا عباراتی که در مجموعه کلی
اسناد رایجتر هستند، امتیاز TF-IDF
کمتری دارند، در حالی که کلمات یا عبارات منحصر به فرد یا کمیابتر، امتیاز بالاتری خواهند داشت.
با استفاده از TF-IDF، مدلهای فضای برداری میتوانند مهمترین کلمات یا عبارات را در یک سند یا مجموعهای از اسناد مشخص کنند. این به مدل اجازه میدهد تا معنی و مفهوم کلمات یا عبارات را درک کند، حتی اگر آنها مترادف یا تغییراتی از کلمات یا عبارات دیگر باشند.
بهطور کلی، مدلهای فضای برداری، مترادفها و تغییرات زبان را با استفاده از بردارهای کلمه و تکنیکهایی مانند جاسازی کلمه و TF-IDF برای درک روابط بین کلمات و عبارات مدیریت میکنند. این به مدل اجازه میدهد تا نتایج موتور جستوجو و بازیابی اسناد را با بازگرداندن نتایج مرتبطتر برای یک کوئری بهبود بخشد، حتی اگر کوئری حاوی کلمات یا عبارات دقیق استفادهشده در اسناد نباشد.

آیا میتوان از
مدلهای فضای برداری برای بهینهسازی رتبهبندی تصاویر و سایر فایلهای چند رسانهای در
نتایج جستوجو استفاده کرد؟
مدلهای فضای برداری که بهعنوان فضاهای برداری یا مدلهای جبر خطی نیز شناخته میشوند، ابزارهای ریاضی هستند که برای نمایش و تحلیل دادههای متنی استفاده میشوند. این مدلها از بردارها یا مجموعهای از مقادیر عددی برای نمایش هر سند یا قطعه متن در یک مجموعه استفاده میکنند.
سپس از این بردارها برای مقایسه و تحلیل روابط بین اسناد مختلف و شناسایی الگوها و روندها استفاده میشود.
یکی از راههایی که میتوان از مدلهای فضای برداری برای بهینهسازی رتبهبندی تصاویر و سایر فایلهای چند رسانهای در نتایج جستوجو
استفاده کرد، استفاده از الگوریتمهای تشخیص تصویر است. این
الگوریتمها محتوای بصری یک تصویر را تجزیهوتحلیل میکنند و آن را با پایگاه دادهای از تصاویر با برچسبهای شناخته شده، مانند «گربه» یا «ساحل» مقایسه میکنند. سپس الگوریتم بر اساس محتوای بصری تصویر، برچسبی را به آن اختصاص میدهد که میتواند برای بهبود نتایج جستوجو استفاده
شود.
برای مثال، اگر کاربر «تصاویر
گربه» را جستوجو کند، موتور جستوجو میتواند از الگوریتمهای تشخیص تصویر برای شناسایی تصاویر حاوی گربهها استفاده کند و آنها را در نتایج جستوجو رتبهبندی کند. این به بهبود دقت و ارتباط نتایج جستوجو کمک میکند؛ زیرا تضمین میکند که کاربر فقط تصاویری را میبیند که مرتبط با درخواست او هستند.
همچنین میتوان از مدلهای فضای برداری برای بهینهسازی رتبهبندی محتوای چندرسانهای، مانند ویدیوها و فایلهای صوتی، با تجزیهوتحلیل محتوای صوتی یا تصویری رسانه و تعیین برچسبها بر اساس محتوای آن استفاده کرد.
برای مثال، یک موتور جستوجوی
ویدئو میتواند از مدلهای فضای برداری برای شناسایی ویدیوهایی که حاوی آهنگ یا
هنرمند خاصی هستند استفاده کند و آنها را در نتایج جستوجو
رتبهبندی کند. این میتواند به ویژه برای کاربرانی که به دنبال انواع خاصی از رسانه هستند مفید باشد؛
زیرا به آنها کمک میکند دقیقاً آنچه را که به دنبال آن هستند راحتتر بیابند.
یکی از مزایای اصلی استفاده از
مدلهای فضای برداری برای جستوجوی تصویر و فایلای چند
رسانهای این است که میتوان آنها را به راحتی در طول زمان بهروز کرد و
بهبود داد. همانطور که تصاویر و فایلهای چند رسانهای جدید به پایگاه داده اضافه میشوند، الگوریتمها را میتوان برای شناسایی و طبقهبندی بهتر آنها بهروز کرد و در نتیجه نتایج جستوجوی دقیق
و مرتبطتری به دست آورد. علاوهبر این، مدلهای فضای برداری را میتوان روی مجموعههای داده بزرگ آموزش داد که به آنها اجازه میدهد تا طیف وسیعی از تصاویر و محتوای چندرسانهای را با دقت طبقهبندی کنند.
با این حال، محدودیتهایی برای استفاده از مدلهای فضای برداری برای جستوجوی تصویر و چند
رسانهای وجود دارد. یک مسئله این است که این مدلها همیشه قادر به طبقهبندی دقیق تصاویر یا چند رسانهای حاوی محتوای پیچیده یا مبهم نیستند. بهعنوان مثال، اگر گربه تا حدی مبهم
باشد یا اگر گربه در حالت غیرعادی باشد، ممکن است بهعنوان یک سگ طبقهبندی شود. این میتواند منجر به عدم دقت در نتایج جستوجو شود
که میتواند برای کاربران خستهکننده باشد.
یکی دیگر از محدودیتهای مدلهای فضای برداری این است که بر کیفیت دادههای مورد استفاده برای آموزش الگوریتمها تکیه میکنند. اگر دادهها ناقص یا نادرست باشند، الگوریتمها قادر به طبقهبندی دقیق تصاویر و چند رسانهای نخواهند بود. اگر دادههای مورد استفاده برای آموزش الگوریتمها نماینده کل مجموعه داده نباشد، ممکن است مشکل ایجاد کند؛ زیرا میتواند منجر به سوگیری در نتایج جستوجو شود.
با وجود این محدودیتها، مدلهای فضای برداری همچنان میتوانند برای بهینهسازی رتبهبندی تصاویر و سایر فایلهای چند رسانهای در نتایج جستوجو بسیار
مفید باشند. این مدلها با تجزیهوتحلیل محتوای تصویری و صوتی
تصاویر و فایلهای چند رسانهای میتوانند به موتورهای جستوجو کمک کنند تا نتایج دقیق و مرتبطتری را به کاربران ارائه دهند. همانطور که الگوریتمهای تشخیص تصویر و طبقهبندی چند رسانهای به بهبود ادامه میدهند، مدلهای فضای برداری احتمالاً به ابزار مهمی برای بهینهسازی رتبهبندی تصاویر و سایر چند رسانهای در نتایج جستوجو تبدیل خواهند شد.
مدلهای فضای برداری چگونه با غلطهای املایی و تایپی در کوئریهای
جستوجو برخورد میکنند؟
مدلهای فضای برداری نوعی مدل ریاضی هستند که در بازیابی اطلاعات و پردازش زبان
طبیعی مورد استفاده قرار میگیرند. آنها برای نمایش معنای کلمات و عبارات به روشی ریاضی استفاده میشوند و امکان مقایسه و دستکاری این معانی را فراهم میکنند.
یکی از چالشهای اصلی در استفاده از مدلهای فضای برداری برای کوئریهای جستوجو، نحوه رسیدگی به غلطهای املایی و تایپی است
که بهدلیل خطای کاربر یا عدم توجه، در جستوجوها رایج هستند.
یکی از راههایی که مدلهای فضای برداری برای مدیریت غلط املایی و
غلط املایی استفاده میکنند، استفاده از الگوریتمهای تصحیح املا است. این الگوریتمها غلط املایی و غلط املایی
را در یک عبارت جستوجو شناسایی میکنند و املا یا غلط املایی
صحیح را پیشنهاد میکنند. این به بهبود دقت نتایج جستوجو کمک میکند؛ زیرا املای صحیح یا اشتباه تایپی احتمالاً به نتایج مرتبطتری منجر میشود.
روش دیگری که مدلهای فضای برداری با املایی و اشتباهات املایی مدیریت میکنند، استفاده از الگوریتمهای تطبیق فازی است. این
الگوریتمها امکان شناسایی کلمات یا عبارات مشابه را
فراهم میکنند، حتی اگر تفاوتهایی در املا یا جملهبندی وجود داشته باشد. این میتواند در مواردی مفید باشد که کاربر کلمهای را اشتباه نوشته باشد یا اشتباه تایپی داشته باشد؛ زیرا نتایج جستوجو
همچنان شامل نتایج مرتبط بر اساس معنای کلمه غلط املایی یا تایپی است.
مدلهای فضای برداری علاوهبر تصحیح املایی و الگوریتمهای تطبیق فازی، میتوانند از بسط مترادف برای مدیریت غلط املایی نیز استفاده کنند. این شامل جایگزینی یک کلمه غلط املایی یا تایپی شده با یک کلمه مترادف یا مرتبط است که میتواند به بهبود دقت نتایج جستوجو کمک کند. بهعنوان مثال، اگر کاربر کلمه «بچه گربه» را جستوجو کند؛ اما آن را اشتباه بهعنوان «بچه کربه» بنویسد، مدل فضای برداری میتواند از بسط مترادف برای جایگزینی «بچه گربه» با «بچه کربه» استفاده کند که منجر به نتایج جستوجوی مرتبطتری میشود.

روش دیگری که توسط مدلهای فضای برداری برای مدیریت غلط املایی و تایپی استفاده میشود، استفاده از مدلهای زبانی است. این مدلها از تکنیکهای آماری برای پیشبینی احتمال استفاده از یک کلمه یا عبارت در یک زمینه خاص، بر اساس کلمات و
عباراتی که معمولاً قبل و بعد از آن ظاهر میشوند، استفاده میکنند. این میتواند در مواردی مفید باشد که کاربر اشتباه تایپی یا املایی داشته باشد؛ زیرا
مدل زبان میتواند کلمه یا عبارت صحیح را بر اساس زمینه کوئری
جستوجو پیشبینی کند.
بهطور کلی، مدلهای فضای برداری از ترکیبی از تصحیح املایی، تطبیق فازی، بسط مترادف و مدلسازی زبان برای مدیریت غلط املایی و تایپی در عبارتهای جستوجو استفاده میکنند. این تکنیکها امکان شناسایی و تصحیح غلطهای املایی و تایپی را
فراهم میکنند که منجر به نتایج جستوجوی دقیقتر و مرتبطتر برای کاربر میشود.
با این حال، توجه به این نکته
مهم است که این تکنیکها بینقص نیستند و ممکن است همیشه نتوانند با دقت غلط املایی و تایپی را مدیریت
کنند، بهویژه اگر کاربر چندین اشتباه مرتکب شده باشد
یا از عبارتهای غیر متعارف استفاده کرده باشد. در این
موارد، نتایج جستوجو ممکن است به اندازه یک کوئری که به درستی املا و تایپ شده
است، مرتبط نباشد.
مدلهای فضای
برداری چگونه تغییرات زبان و اصطلاحات را در طول زمان مدیریت میکنند؟
مدلهای فضای برداری نوعی نمایش ریاضی هستند که در پردازش زبان طبیعی و سیستمهای بازیابی اطلاعات استفاده میشوند. آنها اجازه میدهند کلمات و اسناد بهعنوان بردار در یک
فضای چند بعدی نمایش داده شوند، جایی که هر بعد مربوط به یک اصطلاح یا مفهوم خاص
است.
این مدلها بهطور گسترده در کاربردهای مختلف از جمله طبقهبندی متن، مدلسازی موضوع و بازیابی اطلاعات استفاده میشوند.
یکی از مزایای کلیدی مدلهای فضای برداری، توانایی آنها در مدیریت تغییرات
زبان و اصطلاحات در طول زمان است. این به این دلیل است که آنها بر تعاریف یا قواعد صریح برای معانی کلمات تکیه نمیکنند، بلکه بیشتر بر روابط بین کلمات و الگوهای استفاده آنها در مجموعهای از متن متکی هستند.
در نتیجه، تا زمانی که روابط زیربنایی
بین کلمات حفظ شود، میتوانند خود را با کلمات جدید و تغییرات در
کاربرد زبان وفق دهند.
بهعنوان مثال، یک مدل فضای برداری
را در نظر بگیرید که بر روی مجموعه بزرگی از متن از دهه ۹۰ میلادی آموزش داده شده
است. اگر از این مدل برای پردازش یک سند از امروز استفاده شود، ممکن است با تعدادی
کلمات یا عبارات جدید مواجه شود که در مجموعه آموزشی وجود نداشته است. با این حال،
مدل همچنان میتواند با در نظر گرفتن زمینهای که در آن ظاهر میشوند و روابط بین آنها و سایر کلمات در سند، معنا پیدا کند.
یکی از راههایی که مدلهای فضای برداری تغییرات زبان و اصطلاحات
را در طول زمان مدیریت میکنند، استفاده از جاسازیهای کلمه است. جاسازیهای کلمه، نمایشهای برداری کمبعدی از کلمات هستند که روابط بین کلمات را در یک پیکره مشخص نشان میدهند. آنها با آموزش یک شبکه عصبی روی مجموعه داده
بزرگی از متن ایجاد میشوند و جاسازیهای کلمه حاصل، الگوهای همزمانی بین کلمات در مجموعه داده را
نشان میدهند.
از آنجایی که جاسازی کلمات از
دادهها آموخته میشود، میتوانند ظرافتهای استفاده از زبان و همچنین تغییرات
اصطلاحات را در طول زمان به تصویر بکشند. بهعنوان مثال، اگر یک کلمه یا عبارت جدید
بهطور گسترده در یک زمینه خاص مورد استفاده قرار گیرد، احتمالاً دارای یک کلمه
منحصربهفرد است که الگوهای استفاده و روابط آن را با کلمات دیگر
منعکس میکند.
روش دیگری که مدلهای فضای برداری تغییرات زبان و اصطلاحات را در طول زمان مدیریت میکنند، استفاده از تعبیههای پویا است. جاسازیهای پویا، جاسازیهایی هستند که در طول زمان بهروزرسانی میشوند تا تغییرات استفاده از زبان را منعکس
کنند. آنها را میتوان روی مجموعه دادهای از متن از یک دوره زمانی خاص آموزش داد و
سپس با در دسترس قرار گرفتن با دادههای جدید بهروز شد. این
به مدل اجازه میدهد تا با تغییرات زبان و اصطلاحات در طول
زمان سازگار شود و در عین حال بازنمایی ثابتی از روابط بین کلمات را حفظ کند.
بهطور خلاصه، مدلهای فضای برداری بهدلیل توانایی آنها در به تصویر کشیدن
روابط بین کلمات و الگوهای استفاده از آنها، برای مدیریت تغییرات در زبان و اصطلاحات در طول زمان مناسب هستند. از طریق
استفاده از جاسازیهای کلمه و جاسازیهای پویا، این مدلها میتوانند با کلمات جدید و تغییرات در استفاده از زبان سازگار شوند و در عین حال
بازنمایی ثابت و دقیقی از روابط زیربنایی بین کلمات حفظ کنند. این موضوع آنها را به ابزاری قدرتمند برای پردازش زبان طبیعی و سیستمهای بازیابی اطلاعات تبدیل میکند که اغلب باید با زبان
و اصطلاحات دائماً در حال تکامل سر و کار داشته باشند.
آیا میتوان از
مدلهای فضای برداری برای بهینهسازی رتبهبندی پستهای رسانههای اجتماعی و سایر محتوای تولید شده توسط کاربر استفاده
کرد؟
مدلهای فضای برداری که بهعنوان مدلهای بردار اصطلاحی نیز
شناخته میشوند، نمایشی ریاضی از رابطه بین یک سند و
مجموعهای از اصطلاحات یا کلمات در آن سند هستند.
در زمینه رسانههای اجتماعی، مدلهای فضای برداری را میتوان برای بهینهسازی رتبهبندی پستها و سایر محتوای تولید شده توسط کاربر با تجزیهوتحلیل
محتوا و تعیین ارتباط و اهمیت هر اصطلاح در زمینه بستر رسانه اجتماعی استفاده کرد.
یکی از راههایی که میتوان از مدلهای فضای برداری برای بهینهسازی رتبهبندی پستهای رسانههای اجتماعی استفاده کرد، از طریق استفاده از اصطلاح-معکوس فراوانی متن (TF-IDF) است. TF-IDF برای سنجش اهمیت یک اصطلاح در یک
سند نسبت به مجموعهای از اسناد استفاده میشود. در زمینه رسانههای اجتماعی، مجموعه اسناد میتواند همه پستها در یک پلتفرم خاص باشد و سند فردی که
مورد تجزیهوتحلیل قرار میگیرد میتواند یک پست واحد باشد. با محاسبه امتیازات TF-IDF
برای هر عبارت در یک پست، مدل فضای برداری میتواند اهمیت آن عبارات را در زمینه پلتفرم رسانه اجتماعی تعیین کند و از آن
اطلاعات برای رتبهبندی پست استفاده کند.
روش دیگری که میتوان از مدلهای فضای برداری برای بهینهسازی رتبهبندی محتوای رسانههای اجتماعی استفاده کرد، استفاده از الگوریتمهای یادگیری ماشینی است. این الگوریتمها را میتوان روی مجموعه داده بزرگی از پستهای رسانههای اجتماعی و معیارهای تعامل مرتبط با آنها (مانند لایکها، نظرات و اشتراکگذاریها) آموزش داد تا الگوها و همبستگیهای بین محتوای یک پست و تعامل آن را بیاموزند. با تجزیهوتحلیل محتوای یک پست جدید و مقایسه آن با الگوهای آموخته شده توسط الگوریتم یادگیری ماشین، مدل فضای برداری میتواند درگیری احتمالی پست را پیشبینی کند و از آن اطلاعات برای رتبهبندی آن استفاده کند.
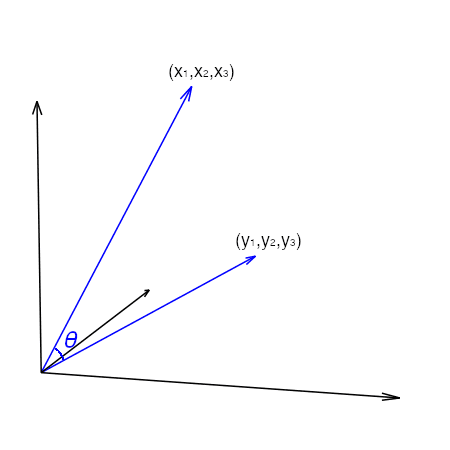
یکی از محدودیتهای بالقوه استفاده از مدلهای فضای برداری برای بهینهسازی رتبهبندی محتوای رسانههای اجتماعی این است که ممکن است همیشه ترجیحات و علایق کاربران را بهطور دقیق منعکس نکنند. مدلهای فضای برداری برای تعیین
ارتباط و اهمیت آن بر وجود و فراوانی عبارات خاصی در یک سند تکیه میکنند؛ اما این ممکن است همیشه عواملی را که باعث تعامل کاربر میشوند را به دقت نشان ندهد. بهعنوان مثال، پستی با تعداد عبارات مرتبط زیاد
ممکن است لزوماً جذابتر از پستی با عبارات مرتبط کمتر نباشد.
یکی دیگر از محدودیتهای استفاده از مدلهای فضای برداری برای بهینهسازی رتبهبندی محتوای رسانههای اجتماعی این است که ممکن است تغییرات در رفتار کاربر یا ترند روی پلتفرم
را در نظر نگیرند. مدلهای فضای برداری بر مجموعه دادههای ثابت تکیه میکنند و ممکن است نتوانند با تغییرات در تنظیمات
یا ترندها در زمان واقعی سازگار شوند. در نتیجه، ممکن است همیشه مرتبطترین یا جذابترین محتوا را برای کاربران در هر لحظه به
درستی منعکس نکنند.
با وجود این محدودیتها، مدلهای فضای برداری همچنان میتوانند ابزار مفیدی برای بهینهسازی رتبهبندی محتوای رسانههای اجتماعی باشند. با تجزیهوتحلیل محتوای
پستها و تعیین ارتباط و اهمیت هر عبارت، مدلهای فضای برداری میتوانند بینش ارزشمندی در مورد عواملی که
باعث تعامل کاربر میشوند ارائه دهند و میتوانند برای رتبهبندی محتوا بر این اساس استفاده شوند. علاوهبر
این، با ترکیب الگوریتمهای یادگیری ماشین، مدلهای فضای برداری میتوانند بهطور مداوم یاد بگیرند و با تغییرات
رفتار و روند کاربر در پلتفرم سازگار شوند و دقت آنها در طول زمان بهبود یابد.
چگونه
مدلهای فضای برداری با تکنیکهای دیگر برای بهینهسازی نتایج جستوجو،
مانند یادگیری ماشینی و هوش مصنوعی مقایسه میشوند؟
مدلهای فضای برداری و الگوریتمهای یادگیری ماشین هر دو
تکنیکهایی هستند که میتوانند برای بهینهسازی نتایج جستوجو مورد استفاده قرار گیرند.
با این حال، برخی از تفاوتهای کلیدی بین این دو رویکرد وجود دارد که آنها را از هم متمایز میکند.
یکی از تفاوتهای اصلی بین مدلهای فضای برداری و الگوریتمهای یادگیری ماشین، نحوه پردازش و تحلیل دادهها است. مدلهای فضای برداری بر اساس یک نمایش ریاضی از
روابط بین نقاط داده مختلف است. این مدلها برای هر نقطه داده یک
بردار ایجاد میکنند و سپس از این بردارها برای نمایش روابط بین نقاط داده استفاده میکنند. این به مدلهای فضای برداری اجازه میدهد تا الگوها و روابط را در مجموعه دادههای بزرگ بهطور دقیق شناسایی کنند.
از سوی دیگر، الگوریتمهای یادگیری ماشین برای یادگیری از دادهها طراحی شدهاند. این الگوریتمها قادر به تجزیهوتحلیل مجموعه دادههای بزرگ و شناسایی الگوها و روابط درون دادهها هستند. سپس میتوانند از این اطلاعات برای پیشبینی یا تصمیمگیری استفاده کنند. الگوریتمهای یادگیری ماشین
معمولاً پیچیدهتر هستند و به قدرت پردازش بیشتری نسبت به
مدلهای فضای برداری نیاز دارند.
یکی دیگر از تفاوتهای کلیدی بین مدلهای فضای برداری و الگوریتمهای یادگیری ماشین، روشی است که از آنها برای بهینهسازی نتایج جستوجو استفاده میشود. مدلهای فضای برداری معمولاً برای بهبود ارتباط نتایج جستوجو با رتبهبندی اسناد بر اساس ارتباط آنها با عبارت جستوجو
استفاده میشوند. این کار با مقایسه بردارهای جستوجو و اسناد موجود در فهرست جستوجو انجام میشود. هر چه بردارها شبیهتر باشند، رتبه سند بالاتر است.
از سوی دیگر، الگوریتمهای یادگیری ماشینی اغلب برای بهبود دقت نتایج جستوجو با پیشبینی قصد کاربر استفاده میشوند. این الگوریتمها میتوانند رفتار کاربر را تجزیهوتحلیل کنند و
از این اطلاعات برای تعیین اینکه کاربر احتمالاً به دنبال چه چیزی میگردد، استفاده میکنند. این به موتور جستوجو اجازه میدهد تا نتایج دقیق و مرتبطتری را برای کاربر
بازگرداند.
همچنین تفاوتهایی در نحوه پیادهسازی مدلهای فضای برداری و الگوریتمهای یادگیری ماشین وجود
دارد. مدلهای فضای برداری معمولاً با استفاده از
الگوریتمهای نرمافزاری پیادهسازی میشوند که برای انجام وظایف خاص برنامهریزی شدهاند. از سوی دیگر، الگوریتمهای یادگیری ماشینی اغلب
با استفاده از شبکههای عصبی پیادهسازی میشوند که سیستمهای پیچیدهای از الگوریتمها هستند که برای تقلید از روشی که مغز انسان کار میکند، طراحی شدهاند.
در نهایت، مدلهای فضای برداری و الگوریتمهای یادگیری ماشین از نظر
مقیاسپذیری و انعطافپذیری متفاوت هستند. مدلهای فضای برداری معمولاً مقیاسپذیرتر از الگوریتمهای یادگیری ماشینی هستند؛ زیرا میتوانند مجموعههای داده بزرگ را کارآمدتر مدیریت کنند. با
این حال، الگوریتمهای یادگیری ماشین معمولاً انعطافپذیرتر از مدلهای فضای برداری هستند؛ زیرا میتوانند در طول زمان از دادههای جدید تطبیق داده و یاد
بگیرند.
در نتیجه، مدلهای فضای برداری و الگوریتمهای یادگیری ماشین هر دو
تکنیکهای مفیدی برای بهینهسازی نتایج جستوجو هستند. مدلهای فضای برداری معمولاً
کارآمدتر و مقیاسپذیرتر هستند، در حالی که الگوریتمهای یادگیری ماشینی انعطافپذیرتر هستند و قادر به
تطبیق با دادههای جدید هستند. هر دو رویکرد نقاط قوت و
محدودیتهای خود را دارند و بهترین رویکرد به نیازهای خاص برنامه بستگی دارد.
ما را دنــــــــــــــــــــــــبال کنید





 تهران، اتوبان خرازی، بلوار نهاوند، جنب مجتمع تجاری رزمال
تهران، اتوبان خرازی، بلوار نهاوند، جنب مجتمع تجاری رزمال
 021-28 4 28 140
021-28 4 28 140